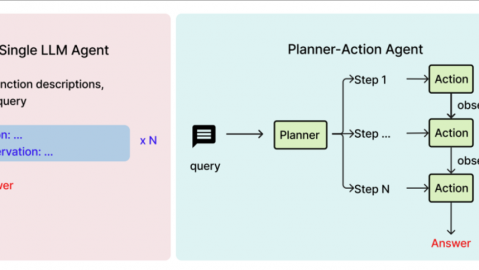
开篇先问大家一个问题:你手机或电脑上的AI聊天助手,是“真记得住”,还是“聊完就忘”?
在2026年的今天,桌面AI聊天助手早已不是新鲜事物。从各大厂商纷纷入局的桌面Agent(智能体)浪潮,到开源社区井喷式涌现的本地化部署方案,这项技术正在经历一场从“能对话”到“能干活”、从“云端依赖”到“本地优先”的根本性转变-5。
然而许多开发者和学习者在接触这一领域时,普遍面临三个痛点:一是只会调用API,不懂底层运行原理;二是混淆RAG(检索增强生成)、Agent、长期记忆等概念之间的关系;三是面试被问到时答不出深度,只会堆术语不会说逻辑。
本文将从基础概念讲起,逐步深入到代码示例和底层原理,帮助读者真正建立起一条完整的知识链路,既看得懂技术逻辑,也答得出面试问题。
一、痛点切入:为什么桌面AI聊天助手需要“本地优先”架构
我们先看一个典型的传统实现方式。
传统云端调用方式(伪代码示意):
传统方式:每次对话都调用云端API def chat(user_input): 每次请求都需要: 1. 携带完整历史记录(token消耗大) 2. 等待云端响应(网络延迟) 3. 数据上传第三方服务器(隐私风险) response = cloud_api.call( model="gpt-4", messages=history + [user_input], api_key=API_KEY ) return response
这段代码虽然简洁,但至少存在四方面的明显缺陷:
数据隐私风险:所有对话内容都上传至云端服务器,敏感信息缺乏安全保障-5
网络依赖性:离线场景下完全不可用,响应受网络质量制约
成本问题:API调用费用随使用量线性增长,高频使用场景成本不菲
上下文窗口有限:长对话需重复传递历史记录,Token消耗大
这些痛点的核心症结在于:传统云端架构把“对话能力”和“数据存储”都外包给了第三方,用户既无法掌控自己的数据,也受限于网络和成本。
2026年的技术演进给出了明确的答案:本地优先 + 开源 Agent。网易有道推出的国内首个全开源桌面级Agent“有道龙虾(LobsterAI)”,正是这一趋势的典型代表——它通过将系统设计核心放在“数据主权”与“本地执行”上,构建了物理级隐私沙箱-5。而阿里巴巴开源的桌面Agent工具CoPaw,则允许开发者自由接入本地模型、自由编写功能,大幅降低了定制化开发的门槛-6。
二、核心概念讲解:RAG(检索增强生成)
定义
RAG的全称是Retrieval-Augmented Generation,中文译为检索增强生成,是一种将外部知识库检索与大模型生成相结合的技术框架-48。
拆解关键词
把这个术语拆开看:
Retrieval(检索) :从知识库中“找”相关信息
Augmented(增强) :把找到的信息“补充”给模型
Generation(生成) :让模型“说”出最终答案
三个词合起来就是:先查资料,再回答问题。
生活化类比
想象一下开卷考试的场景——
没有RAG的模型就像闭卷考试的学生:只能靠大脑里已有的知识答题,遇到没学过的内容就会瞎编(也就是所谓的“幻觉”)。
而有RAG的模型就像带参考书考试的学生:答题前先翻书查找相关知识点,把查到的信息作为参考,再结合自己的理解来作答-48。
核心解决的问题
RAG主要解决了大模型的两大痛点:一是知识滞后(模型训练数据的截止时间之后的信息一概不知),二是容易产生幻觉(编造不存在的答案)-48。
三、关联概念讲解:Ollama
定义
Ollama 是一款开源的本地大模型运行与管理工具,其核心定位是让开发者能够以极低的成本在本地环境部署和运行主流大模型-48。
它与RAG的关系
RAG和Ollama的关系可以这样理解:RAG是“怎么做”的方法论,Ollama是“用什么做”的工具之一。
RAG定义了一种技术范式:检索 → 增强 → 生成
Ollama提供了一个执行载体:在本地跑模型,让RAG可以完全离线运作
在实际项目中,Ollama常常作为RAG架构的“生成引擎”——负责最后一步的答案生成,而检索部分则由向量数据库或其他检索模块负责。
核心优势
Ollama最大的特点是极简部署:一行命令即可拉取并启动通义千问、Llama3等数十种主流大模型,无需手动配置CUDA、依赖库等复杂环境-48。2026年初,Ollama还集成了苹果MLX框架,在Mac设备上的推理速度最高可翻倍-。与此同时,llama.cpp项目也在2026年初迈过了成熟门槛,其Metal和CUDA后端、模型管理以及上下文窗口处理都已趋于稳定-。
四、概念关系与区别总结
梳理一下本文涉及的核心概念关系:
| 概念 | 定位 | 一句话理解 |
|---|---|---|
| Agent(智能体) | 顶层设计 | 能主动规划、自主执行任务的AI系统 |
| RAG | 技术范式 | “查资料再回答”的方法论 |
| Ollama | 基础设施工具 | 在本地运行大模型的“引擎” |
| 长期记忆 | 核心能力 | 跨会话保留用户信息,实现个性化交互 |
记忆口诀:Agent是大脑,RAG是工作方法,Ollama是引擎,长期记忆是档案库。这四者层层嵌套、相互配合,共同构成完整的桌面AI聊天助手技术栈。
五、代码示例:搭建一个本地化RAG问答系统
下面通过一个简洁可运行的示例,演示如何用Ollama + 向量检索构建一个本地化RAG系统。所有代码均可在本地环境运行,不依赖任何云端API。
环境准备
1. 安装 Ollama(一行命令,支持 Linux/macOS/Windows WSL2) curl -fsSL https://ollama.com/install.sh | sh 2. 拉取并运行模型(以千问2B轻量版为例,适合本地测试) ollama pull qwen2:1.5b ollama run qwen2:1.5b
RAG核心代码
rag_demo.py - 本地RAG问答系统示例 import ollama import chromadb from chromadb.utils import embedding_functions 步骤1:初始化本地向量数据库(Chromadb) client = chromadb.Client() collection = client.create_collection( name="knowledge_base", embedding_function=embedding_functions.OllamaEmbeddingFunction( model_name="nomic-embed-text" 本地嵌入模型 ) ) 步骤2:准备知识库文档并入库 documents = [ "Ollama是一个本地大模型运行工具,支持Llama、Qwen等模型", "RAG通过检索外部知识来增强LLM的回答准确性", "本地部署的核心优势包括数据隐私保护和离线可用性" ] collection.add( ids=["doc1", "doc2", "doc3"], documents=documents ) 步骤3:定义RAG问答函数 def rag_query(user_question: str) -> str: 检索:从知识库中查找相关文档 results = collection.query( query_texts=[user_question], n_results=2 返回最相关的2条 ) 增强:将检索到的知识拼接到上下文 context = "\n".join(results['documents'][0]) augmented_prompt = f""" 基于以下参考信息回答问题。如果参考信息中没有答案,请如实告知。 参考信息: {context} 问题:{user_question} 回答: """ 生成:调用本地LLM生成答案 response = ollama.chat( model='qwen2:1.5b', messages=[{'role': 'user', 'content': augmented_prompt}] ) return response['message']['content'] 步骤4:测试运行 if __name__ == "__main__": answer = rag_query("Ollama是什么?它有什么优势?") print("AI回答:", answer)
关键步骤说明
检索(第15-21行):用Ollama内置的嵌入模型将用户问题向量化,在本地向量库中做语义相似度匹配
增强(第23-31行):把检索到的知识文档拼接到Prompt中,作为模型回答的参考依据
生成(第33-38行):调用本地运行的Qwen2模型,基于增强后的Prompt生成最终答案
这个示例虽然只有不到50行代码,但完整展示了RAG“检索 → 增强 → 生成”的核心流程,并且全程在本地运行,无需任何云端API。
六、底层原理 / 技术支撑
要让上述RAG系统真正跑起来、跑得稳,底层依赖以下三个关键技术支撑:
1. 向量检索与嵌入模型
RAG的第一步“检索”,本质上是语义而非传统的关键词匹配。计算机无法直接理解文本的“含义”,因此需要将文本通过嵌入模型(Embedding Model)转化为高维向量——也就是一串数字化的“语义指纹”-48。相似含义的文本在向量空间中距离更近,便于快速检索。常用的嵌入模型包括BGE、Sentence-BERT以及Ollama内置的nomic-embed-text等。
2. 量化技术与内存优化
在本地电脑上运行大模型并非易事。一个70亿参数的模型以FP32精度加载,仅权重就需要约28GB显存,普通消费级设备根本无法承载。量化的核心思路是:用更少的位数表示模型权重(比如把32位浮点数压缩到4位整数),以精度换显存。llama.cpp框架在这一领域处于领先地位,其GGUF格式配合FP4级别加速,让大模型在消费级GPU上运行成为现实-。
3. 长期记忆的工程化实现
对话AI的长期记忆是一个系统级的工程挑战。2026年的技术方案呈现出从“向量存储”到“分层架构”的演进趋势。一种典型的实现是三级记忆库架构:核心记忆库存储最关键、不可删除的信息并“上锁”保护;中层记忆库存放比较重要但可动态更新的内容;临时缓存库处理不确定的信息,由模型自动筛选和用户反馈确认后方可升级入库-57。这种方式让AI真正做到“记得住、不啰嗦、不乱记”。
七、高频面试题与参考答案
以下精选5道与桌面AI聊天助手相关的高频面试题,附标准答题思路。
面试题1:什么是RAG?它和Fine-tuning有什么区别?
参考答案(建议用时1.5分钟内):
RAG(Retrieval-Augmented Generation)是一种将外部知识检索与大模型生成相结合的技术范式,核心流程是“检索 → 增强 → 生成”-48。
与Fine-tuning的区别有三点:
数据需求:RAG无需标注数据,Fine-tuning需要高质量标注数据
时效性:RAG可实时检索最新信息,Fine-tuning受训练数据时间限制
成本:RAG无模型训练成本,Fine-tuning需要大量计算资源
一句话总结:RAG适合知识动态更新的场景,Fine-tuning适合风格/行为固定的场景。
面试题2:如何设计一个AI Agent的长期记忆系统?
参考答案(踩分点:分层架构 + 生命周期管理):
分层存储:将记忆分为核心记忆(用户关键信息,不可删除)、工作记忆(当前会话上下文)、长期记忆(跨会话持久化),分层管理-57。
生命周期管理:采用“提取-存储-检索-注入”四大模块,支持动态更新与低频遗忘治理-61。
入库过滤机制:通过模型自动识别+用户反馈确认两层过滤,确保只存储真正有价值的信息,避免记忆库膨胀-57。
性能考量:记忆检索响应时间优化,可结合向量检索与关键词检索实现混合召回-47。
面试题3:Agent和传统聊天机器人的本质区别是什么?
参考答案:
交互模式不同:传统聊天机器人是被动响应(用户问 → AI答),Agent是主动规划(理解目标 → 拆解步骤 → 执行任务)-23。
能力边界不同:传统聊天机器人停留在“对话”,Agent扩展到“操作”——能打开软件、点击按钮、读写文件、调用API。
架构复杂度不同:Agent需要工具调用(Tool Use)、记忆管理、规划推理三大模块协同工作。
一句话总结:聊天机器人是“会说话的工具”,Agent是“会干活的同事”。
面试题4:Ollama与llama.cpp的区别是什么?如何选型?
参考答案:
定位差异:Ollama是“应用层工具”,封装了模型管理、API服务、推理调度,开箱即用;llama.cpp是“底层框架”,提供C++推理引擎,更底层但更灵活--。
适用场景:
快速原型/教学演示 → Ollama(一行命令搞定)
生产环境/嵌入式/极致性能 → llama.cpp(可深度调优)
Mac用户 → Ollama + MLX集成,推理速度翻倍-
关系说明:Ollama底层依赖llama.cpp作为推理引擎,两者是“封装”与“被封装”的关系。
面试题5:本地部署大模型面临哪些挑战?如何应对?
参考答案(踩分点:硬件 + 存储 + 能力):
硬件限制:消费级设备显存/内存有限 → 应对策略:模型量化(FP4/INT8)、选择轻量模型(1.5B-7B)、利用CPU+共享内存。
知识滞后:本地模型知识截止时间固定 → 应对策略:RAG接入本地知识库,实时检索补充。
能力局限:本地小模型推理能力弱于云端大模型 → 应对策略:任务拆分、特定场景微调、混合架构(本地处理敏感数据 + 云端处理复杂推理)。
八、结尾总结
回顾全文的核心知识点:
本地优先是2026年桌面AI助手的核心趋势。从网易有道LobsterAI到阿里CoPaw,从OpenClaw到UI-TARS-desktop,开源桌面Agent正在打破云端垄断-5-6。
RAG是解决大模型知识滞后和幻觉的关键技术范式,核心流程可概括为“检索 → 增强 → 生成”三步-48。
Ollama和llama.cpp是本地化部署的两大基石。前者主打开箱即用,后者追求极致性能,两者配合可以搭建完全离线的AI聊天系统。
长期记忆系统是Agent从“玩具”走向“生产力工具”的关键基础设施,其核心设计思路是分层存储 + 生命周期管理-61。
理解概念之间的逻辑关系是面试高分的秘诀:Agent是顶层设计,RAG是方法范式,Ollama是落地工具,长期记忆是核心能力——四者层层递进、缺一不可。
如果本文对你有所帮助,欢迎点赞收藏。下一篇将深入拆解AI Agent的核心架构——从工具调用(Tool Use)到规划推理(Planning),带你一步步从“会用API”走向“真正理解Agent”。敬请期待!