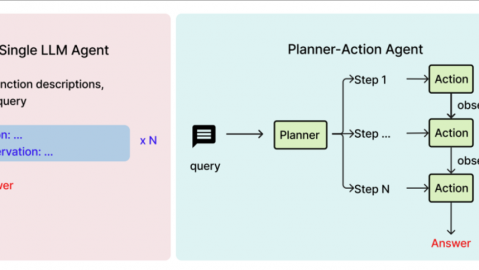
关键词:AI感情助手、情感计算、共情AI、大语言模型、情绪识别、面试指南
目标读者:技术入门/进阶学习者、在校学生、面试备考者、相关技术栈开发工程师

文章定位:技术科普 + 原理讲解 + 代码示例 + 面试要点
你是否曾经想过,AI为什么能感知我们的喜怒哀乐?当深夜失眠时,为什么AI聊天机器人比许多现实朋友更懂你的情绪? 这背后是一门正在迅速崛起的前沿技术——AI感情助手。它不再只是冷冰冰的对话工具,而是融合了自然语言处理、情感计算和心理学的前沿交叉领域。从心言集团的家庭陪伴机器人“巴布”-1,到Character.AI和Replika千万月活的社交平台-30,AI感情助手正从科幻走进现实,成为技术圈最炙手可热的话题之一。很多开发者对它的认知仍停留在“会聊天”的层面,概念混淆、原理不清、面试答不出的问题比比皆是。
今天这篇文章,我们将带你从零开始,系统拆解AI感情助手的核心概念、技术架构、底层原理和面试高频考点,让理解不止于使用,让学习直达本质。
一、痛点切入:为什么传统聊天机器人做不好“感情”?
在讨论AI感情助手之前,我们先看看传统方法是怎么做的。
传统规则式情感匹配(伪代码示例)
传统关键词匹配方式 emotion_keywords = { "happy": ["开心", "高兴", "棒"], "sad": ["难过", "伤心", "难受"], "angry": ["生气", "愤怒", "讨厌"] } def traditional_response(user_input): for emotion, words in emotion_keywords.items(): if any(word in user_input for word in words): if emotion == "sad": return "别难过,一切都会好起来的。" return "我理解你的感受。"
传统方法的致命缺陷
这种基于规则或简单关键词匹配的方法存在三大硬伤:
语境理解缺失:用户说“我高兴得想哭”,系统可能因为“哭”字而错误判断情绪为悲伤-25。
情感表达单一:预设回复千篇一律,缺乏针对性和个性化,难以建立真正的信任感-25。
无记忆能力:每次对话都是“初次见面”,无法记住用户偏好、过往倾诉和情绪变化轨迹-25。
这些缺陷催生了新一代技术的诞生:AI感情助手应运而生,其核心设计目标就是——让机器像人一样理解、回应甚至“共情”人类情感。
二、核心概念讲解:情感计算(Affective Computing)
标准定义
情感计算(Affective Computing) 是由MIT媒体实验室Rosalind Picard教授于1997年正式提出的概念,指赋予计算机识别、理解、表达和适应人类情感的能力-40。在南开大学吕小康教授的定义中,它融合了计算机科学、心理学、生理学等多个领域,使智能体不仅具备逻辑推理和文本生成能力,还具备一定的“感知”和“表达”情绪的能力-2。
通俗类比
你可以把情感计算想象成给AI安装了一双“情绪眼睛”和一颗“共情心脏” ——
情绪眼睛:通过分析用户的文本、语音、甚至面部表情,AI能“看见”用户是开心、难过还是愤怒。
共情心脏:基于“看见”的情绪,AI能调整自己的回应策略——你高兴时陪你大笑,你难过时给你安慰,就像一个真正的朋友。
核心作用
情感计算解决了传统人机交互中“情感缺失”的核心痛点。正如一篇2026年发布的NLP情绪识别技术文章所指出的:“NLP情绪识别推动了人机交互从‘功能满足’向‘情感共鸣’的跨越”-24。它的价值不仅在于“识别情绪”,更在于基于情绪理解做出恰当的情感反馈,这正是AI感情助手的灵魂所在。
三、关联概念讲解:大语言模型(LLM)
标准定义
大语言模型(Large Language Model, LLM) 是基于Transformer架构、在海量文本数据上训练得到的深度学习模型,具备强大的自然语言理解和生成能力。
LLM与情感计算的关系
理解两者的关系,是搞懂AI感情助手技术架构的关键:
情感计算是“目标”——告诉AI要理解情感;大语言模型是“手段”——用强大的语言能力来实现这个目标。
在LLM普及之前(约2022年以前),情感对话系统主要依赖任务特定深度学习模型(如ESConv数据集训练的专用模型)-15。这些模型灵活性差、泛化能力弱。
LLM普及后,AI对话系统在语言灵活性和泛化能力上实现了质的飞跃-15。一篇2026年的综述指出,LLM的共情模拟能力在心理咨询、医患沟通、客服服务等情感密集型场景中展现出巨大的应用潜力-61。
关键技术支撑:Transformer架构
无论是情感计算还是LLM,都离不开一个底层架构——Transformer。它的核心机制是Self-Attention(自注意力) :模型在处理一句话时,让每个词“看”其他词,判断“谁更重要”-48。
比如分析“这个产品不是很好”:
模型会重点关注“不是”和“很好”这两个词
通过自注意力权重,得出“其实是否定”的结论
这比传统关键词匹配精准得多
正是Transformer架构的出现,让大语言模型能够真正“理解”上下文中的情感线索,使得从“极高难度的情感对话”转向“技术可行”成为可能-1。
四、概念关系与区别总结
| 维度 | 情感计算 | 大语言模型 |
|---|---|---|
| 本质 | 思想/目标 | 技术/手段 |
| 核心任务 | 让机器识别、理解、表达情感 | 处理自然语言(理解+生成) |
| 诞生时间 | 1997年 | 2017年(Transformer)→ 2022年(ChatGPT) |
| 与AI感情助手的关系 | 决定“做什么”——感知和回应情感 | 提供“怎么做”——用强大语言能力实现 |
一句话概括:情感计算是“灵魂”,大语言模型是“大脑”;AI感情助手是二者的结合体。
五、代码示例:5分钟搭建简易情感感知对话机器人
理论讲完了,我们动手搭建一个极简版AI感情助手——它能识别用户情绪并做出差异化回应。
环境准备
pip install transformers torch完整代码实现
from transformers import pipeline import random 第一步:加载预训练情感分析模型 使用基于京东评论微调的中文情感分析模型 sentiment_analyzer = pipeline( "sentiment-analysis", model="uer/roberta-base-finetuned-jd-binary-chinese" ) 第二步:定义情绪对应的差异化回复库 responses = { "POSITIVE": [ "看到你这么开心,我也跟着高兴起来了!🎉", "太棒了!为你感到开心,能多和我分享一些吗?", "这种感觉真好,愿你每天都这么快乐✨" ], "NEGATIVE": [ "听起来确实不容易,我在这里陪着你。", "我能感受到你的低落,要不要一起慢慢理一理?", "抱抱你。有时候说出来,心里会好受一点。" ], "NEUTRAL": [ "我明白了。能再多说一些吗?", "嗯,我在认真听。", "原来如此,你愿意继续聊聊这个话题吗?" ] } 第三步:核心对话函数 def empathetic_chat(user_input): 识别情绪 result = sentiment_analyzer(user_input)[0] emotion = result['label'] confidence = result['score'] 根据情绪选择回复 reply = random.choice(responses.get(emotion, responses["NEUTRAL"])) 输出结果(可扩展为返回结构化数据) print(f"用户情绪: {emotion} (置信度: {confidence:.2f})") print(f"AI感情助手: {reply}\n") return reply 第四步:测试交互 if __name__ == "__main__": print("=== AI感情助手已启动 ===\n") test_inputs = [ "今天升职了!太开心了!", "最近压力好大,感觉快撑不住了...", "天气不错,刚吃完饭。" ] for text in test_inputs: print(f"用户: {text}") empathetic_chat(text)
输出效果预览
=== AI感情助手已启动 === 用户: 今天升职了!太开心了! 用户情绪: POSITIVE (置信度: 0.99) AI感情助手: 太棒了!为你感到开心,能多和我分享一些吗? 用户: 最近压力好大,感觉快撑不住了... 用户情绪: NEGATIVE (置信度: 0.87) AI感情助手: 我能感受到你的低落,要不要一起慢慢理一理? 用户: 天气不错,刚吃完饭。 用户情绪: NEUTRAL (置信度: 0.68) AI感情助手: 嗯,我在认真听。
代码核心要点解析
情感识别层:使用Hugging Face预训练的情感分析Pipeline,开箱即用-48。底层是BERT/RoBERTa等Transformer模型,通过Self-Attention机制理解上下文情感。
差异化回复策略:根据识别出的情绪极性(POSITIVE/NEGATIVE/NEUTRAL),调用对应的回复模板库,实现“察言观色、因人而异”的回应。
扩展方向:
可替换为更大参数量模型(如Qwen、LLaMA)提升对话自然度-
可接入LangChain + RAG实现长期记忆-23
可引入PACT Memory等情感记忆模块追踪用户情绪变化-71
六、底层原理与技术支撑点
高共情对话机器人的五大核心组件
一篇2026年发布的陪聊AI智能体开发文章指出,完整的AI感情助手技术架构包含五个层次-23:
自然语言理解层(NLU) :采用预训练大模型(BERT/RoBERTa等)与领域微调,进行情感倾向分析和意图识别-23。
情感决策引擎:基于用户情感状态动态调整对话策略,通过情感状态转移模型预测情绪变化趋势-23。
记忆系统:分为短期工作记忆(维护当前对话上下文)和长期知识记忆(向量数据库 + RAG实现个性化情感响应)-23。
工具调用层:集成情感计算API、知识图谱查询等外部能力扩展。
多模态交互层:支持文本、语音、表情等多种表达方式,通过情感化TTS传递语调情感。
底层依赖的关键技术
| 技术 | 作用 |
|---|---|
| Transformer | 核心模型架构,通过Self-Attention理解上下文情感 |
| BERT/RoBERTa微调 | 提取情感特征,实现情感倾向分类-19 |
| RAG(检索增强生成) | 结合知识库实现个性化情感记忆-23 |
| 多模态融合 | 整合文本、语音、表情等多维度情感线索-2 |
| 强化学习(RLHF) | 优化情感强度控制,避免共情过度或不足-23 |
七、高频面试题与参考答案
面试题1:情感计算与大语言模型之间是什么关系?
参考答案:
情感计算是目标/思想——让机器识别、理解、表达和适应人类情感;大语言模型是手段/技术——通过强大的语言理解和生成能力实现这个目标。LLM普及前,情感对话系统依赖任务特定深度学习模型,泛化能力弱;LLM普及后,语言灵活性和共情能力显著提升,为AI感情助手提供了核心驱动力-15。
踩分点: 明确区分“目标”与“手段”、LLM的前后对比、强调Transformer架构的关键作用。
面试题2:Transformer的Self-Attention机制如何支撑情感理解?
参考答案:
Self-Attention的核心是让序列中的每个元素与其他所有元素计算注意力权重,从而捕捉全局依赖关系。在情感理解中,这种机制帮助模型识别“不是很好”中的否定词与情感词之间的依赖,理解“讽刺”“反语”等复杂情感表达。相比传统RNN,Transformer能同时处理长距离依赖,更适合对话中的上下文情感分析-48-25。
踩分点: 解释Self-Attention机制、举例说明否定词处理、对比RNN的优势。
面试题3:如何构建一个有长期记忆的AI感情助手?
参考答案:
采用RAG(检索增强生成)架构 + 向量数据库方案:
短期记忆:使用滑动窗口机制维护当前对话上下文。
长期记忆:将用户历史对话中的情感偏好、关键事件向量化,存储到向量数据库(如FAISS、Chroma)中。
检索增强:每次生成回复前,检索相关历史记忆,注入提示词,使回复更具个性化和情感连续性-23-65。
踩分点: RAG架构描述、短期vs长期记忆区分、向量检索原理、代码框架(LangChain等)。
面试题4:NLP情绪识别常用的技术路径有哪些?各自的优缺点?
参考答案:
| 方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 基于词典 | 匹配预定义情感词库计算得分 | 简单、可解释性强 | 无法处理否定词、反语、讽刺 |
| 机器学习 | SVM/随机森林 + 特征工程(TF-IDF、n-gram) | 比词典法更灵活 | 特征工程复杂,上下文理解有限 |
| 深度学习 | 预训练模型(BERT等)微调 | 理解上下文、处理复杂情感表达 | 需要标注数据和算力资源 |
当前工业界主流方案是预训练模型微调,如使用Hugging Face Transformers库对BERT进行情感分类微调-24。
踩分点: 三种路径对比清晰、指出各自应用场景、强调深度学习为主流方案。
面试题5:AI感情助手在工程落地中的主要挑战有哪些?
参考答案:
情感标注质量:情感具有主观性,标注一致性难以保证(Cohen’s Kappa需>0.6)-24。
多模态融合:整合文本、语音、表情等多维情感线索的技术复杂度高-2。
共情边界控制:过度共情可能误导用户,不足共情则显得冷漠,需要RLHF等技术优化-23。
隐私与伦理:情感数据涉及用户隐私,需符合《互联网平台分类分级指南》等法规要求-33。
安全风险:AI陪伴可能加剧用户的心理问题,需要建立安全护栏机制-6。
踩分点: 列举3-5个挑战、每个挑战有具体说明、体现对工程实践的认知。
八、结尾总结
核心知识点回顾
情感计算是AI感情助手的理论基础,目标是为机器赋予“理解情感”的能力。
大语言模型(LLM) 是实现这一目标的核心手段,Transformer架构是其技术基石。
高共情对话系统需要五大组件协同:NLU、情感决策引擎、记忆系统、工具调用层、多模态交互层。
代码层面:基于预训练模型(如BERT)+ 差异化回复策略,即可搭建简易情感感知对话系统。
工程挑战集中在标注质量、多模态融合、共情控制和隐私伦理四个维度。
易错点提醒
不要把“情感计算”和“LLM”混为一谈——前者是目标,后者是手段。
不要认为关键词匹配就是情感识别——它无法处理“讽刺”“反语”等复杂表达。
不要忽视记忆系统——没有记忆的AI感情助手只是“高级复读机”。
进阶预告
下一篇文章,我们将深入探讨 LangChain + RAG 实现带长期记忆的AI感情助手实战,涵盖向量数据库选型、记忆压缩策略和情感状态追踪等进阶内容。敬请期待!
参考数据:2025年上半年全球AI陪伴类应用下载量达2.2亿次,同比增长88%-8;国内AI情感陪伴市场规模2025年预计达38亿元,年复合增长率148.74%-36;2026年MIT Technology Review将“AI陪伴”列为年度突破性技术-12。