你是否也遇到过这样的场景:想让手机助手帮你“订一张下周去上海的高铁票,顺便在沿途找一家评分高的咖啡店”,它要么回答“我没听懂”,要么只打开一个App等你手动操作?
这不是你的错觉。市面上绝大多数AI手机助手,本质上仍是一个独立App,拿不到系统底层接口,自然无法完成跨步骤的自动化任务-。真正的AI手机助手——那个能听懂模糊指令、自主跨越多个App执行复杂任务的智能体,正在从概念走向现实。

本文将从传统语音助手 vs AI智能体的对比切入,剖析“GUI模拟”与“API协同”两条技术路线,用代码示例演示智能体的核心运行机制,最后梳理高频面试题。读完这篇,你将建立起从“只会用”到“懂原理”的完整知识链路。
一、痛点切入:为什么传统语音助手不够用?

先看一段传统语音助手的典型代码:
传统语音助手 —— 命令映射模式 def voice_assistant(command): if "打开" in command and "微信" in command: launch_app("wechat") return "已为您打开微信" elif "导航到" in command: address = extract_address(command) launch_app("maps", query=address) return f"已打开地图,前往{address}" elif "订票" in command: 无法完成 —— 需要跨App操作 return "抱歉,我需要你手动打开订票App" else: return "我没听懂,请再说一遍"
这种命令映射式的实现方式存在明显缺陷:
耦合高:每个指令都需要预先硬编码对应的动作
扩展性差:新增一个功能就要改代码、发版本
执行能力弱:只能做“打开App”或“”这类单步操作,无法完成“比价→下单→转发截图”这类跨应用流程-5
缺乏情境感知:当你心急慌忙地说“帮我订个最早的机票”,和笃悠悠地说“帮我找个周末的好去处”,传统助手给出的答案几乎一样——它读不懂语气差异-7
新一代AI手机助手是如何解决这些问题的?
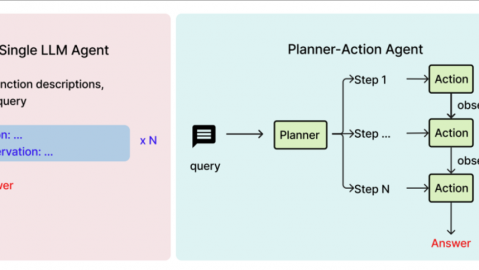
二、核心概念:AI智能体(AI Agent)
AI Agent(人工智能智能体) 是一种能够感知环境、自主规划并执行任务以实现特定目标的智能系统。区别于传统助手“问答式”的被动响应,Agent具备主动思考、主动执行、主动闭环的能力-2。
可以用一个比喻来理解:
传统语音助手像一个“听话的遥控器”:你说“换到CCTV”,它就帮你换台。但它不会主动理解你为什么想看新闻,更不会帮你分析新闻内容。
AI智能体像一个“懂你的私人助理”:你说“帮我规划下周去上海的行程”,它会主动查机票、比较酒店、安排日程,然后把完整的方案交给你——全程不需要你打开任何一个App。
Agent的核心运行机制可以概括为三个环节:
感知:通过摄像头、麦克风、传感器实时获取环境信息
规划:利用大模型解析用户真实意图,拆解任务为多个步骤
执行:模拟点击或调用API,逐步完成任务并处理异常-2
三、关联概念:GUI模拟 vs API协同
实现AI手机智能体,目前有两条主流技术路线。
概念A:GUI模拟
GUI模拟(Graphical User Interface Simulation) ,指智能体通过系统级权限读取屏幕内容并模拟用户点击来实现跨应用自动化操作-6。
其核心原理是:利用系统权限充当 “虚拟手指” ——先“看懂”屏幕上有什么,再“点”对应的位置。最初的技术实现依赖Android的无障碍服务(Accessibility Service) ,这项权限本是为视障人士设计的-6。现在豆包手机助手等产品采用了更激进的INJECT_EVENTS权限,可直接向系统注入点击、滑动等用户操作事件-6。
优点:无需App方配合,理论上有极高的通用性
缺点:隐私风险大,可能被恶意利用,且与灰产脚本在技术上高度同构-6
概念B:API协同
API协同(Application Programming Interface Coordination) ,指智能体通过App提供的标准化接口进行数据交互和指令传达-6。
这更像一条 “正规军”路线:App主动开放接口,Agent通过接口调用功能,整个过程可控、可审计、安全合规。
优点:安全可控,符合软件工程规范
缺点:需要App厂商逐一适配,生态建设周期长
一句话概括两者的关系
GUI模拟是“破墙而入”的捷径,API协同是“开门迎客”的正道。
| 对比维度 | GUI模拟 | API协同 |
|---|---|---|
| 本质 | 模拟人类操作 | 调用标准接口 |
| 通用性 | 高,无需App适配 | 低,需逐一对接 |
| 隐私安全 | 风险较高 | 可控 |
| 落地速度 | 快 | 慢 |
四、代码示例:一个极简GUI模拟Agent
下面是一个简化版的GUI模拟Agent核心逻辑,展示了“看懂屏幕→找到目标→点击操作”的基本流程:
import cv2 import pyautogui class SimpleGUIAgent: def __init__(self): self.screen_reader = ScreenReader() 屏幕读取模块 self.clicker = ClickSimulator() 点击模拟模块 def execute_task(self, instruction): 步骤1:大模型解析用户意图 target = self.llm_parse(instruction) "帮我找到'提交订单'按钮" 步骤2:截取当前屏幕 screenshot = self.screen_reader.capture() 步骤3:视觉识别目标元素 coordinates = self.vision_model.locate(screenshot, target) 返回: {'x': 540, 'y': 1280, 'element': '提交订单'} 步骤4:模拟点击 self.clicker.tap(coordinates['x'], coordinates['y']) 步骤5:等待页面跳转,循环执行直到任务完成 while not self.is_task_completed(): screenshot = self.screen_reader.capture() next_action = self.planner.next_step(screenshot) self.execute_action(next_action)
关键步骤解读:
LLM解析:把用户说“帮我订个外卖”转化为“打开美团→附近餐厅→选择→提交订单”的步骤序列
视觉定位:用多模态大模型识别屏幕上的按钮、图标位置
模拟点击:通过系统权限注入点击事件,替代人类手指
闭环执行:每一步后重新截屏确认状态,遇到弹窗自动处理-5
五、底层技术支撑
GUI模拟Agent看似简单,背后依赖三大技术支柱:
| 技术层 | 具体依赖 | 作用 |
|---|---|---|
| 模型层 | 端侧大模型(如Gemma 4 E4B、MiMo) | 解析意图、规划步骤、识别屏幕元素 |
| 算力层 | 手机NPU(如骁龙8至尊版,200TOPS级算力) | 支撑端侧推理,毫秒级响应 |
| 权限层 | 系统注入权限(INJECT_EVENTS / 无障碍服务) | 实现跨应用点击操作 |
为什么现在才成为可能? 三年前,大模型动辄数百亿参数,手机根本装不下;NPU算力不足,模型推理会严重发热。转折出现在芯片算力数倍跃升 + 模型压缩技术从“缩水版”进化为“本地专家”-7。
华为的小艺Claw、小米的超级小爱V7.12等产品,正是依赖这些底层能力的成熟,才真正具备了本地部署、主动执行的Agent能力-21-34。
六、高频面试题与参考答案
Q1:传统语音助手和AI智能体的核心区别是什么?
参考回答:
传统语音助手是基于命令映射的被动问答系统,用户说什么它做什么,无法完成多步骤任务。AI智能体是感知-规划-执行闭环的自主系统,能解析模糊意图、自主拆解任务、跨应用执行操作。前者像“遥控器”,后者像“私人助理”。(4个关键词:主动/被动、规划/映射、执行/打开、跨应用/单应用)
Q2:手机AI智能体有哪两种主要技术实现路线?各有什么优缺点?
参考回答:
一是GUI模拟:利用系统权限“读懂”屏幕并模拟点击,通用性强落地快,但隐私风险高。二是API协同:通过App开放的标准接口调用功能,安全可控但需生态配合。前者是“破墙而入”的捷径,后者是“开门迎客”的正道。
Q3:为什么2026年AI手机才开始真正普及?
参考回答:
三大拐点:①芯片算力:NPU算力两年实现数倍跃升,端侧推理200TOPS成为现实;②模型压缩:Gemma 4等模型实现端侧部署,参数效率提升超10倍;③隐私技术:端侧加密、不存不训原则消除了用户顾虑。
Q4:GUI模拟Agent是如何实现“看懂屏幕并点击”的?
参考回答:
核心三步:①多模态大模型识别屏幕截图中的UI元素并返回坐标;②LLM将自然语言指令拆解为步骤序列;③系统注入权限(INJECT_EVENTS/无障碍服务)模拟点击事件。每一步后重新截屏确认,形成闭环执行。
Q5:谈谈你对AI手机未来趋势的看法。
参考回答:
IDC预测2026年中国新一代AI手机出货量1.47亿台,占比首次过半-5。技术趋势上,端云协同将成主流:云端处理复杂推理,端侧保证实时响应与隐私-7。长远来看,AI Agent可能重塑人机交互——从“操作App”转向“语音驱动一切”的无App计算时代-10。
七、结尾总结
本文核心知识点速览:
| 章节 | 核心内容 | 一句话记住 |
|---|---|---|
| 痛点切入 | 传统助手只能“打开App”,无法“完成任务” | 能力停留在单步操作 |
| AI Agent | 感知→规划→执行的闭环系统 | 从“听话”到“懂事” |
| GUI模拟 vs API协同 | 破墙而入 vs 开门迎客 | 前者通用快,后者安全慢 |
| 代码示例 | 截图→识别→点击→循环 | “看懂再点”的自动化 |
| 底层支撑 | NPU算力 + 端侧大模型 + 系统权限 | 三位一体,缺一不可 |
重点提示:面试时务必区分 “Agent vs Assistant” 的本质差异,说清楚两种技术路线的权衡,这是当前AI手机赛道的核心命题。
进阶预告:下一篇将深入端侧大模型的部署优化——如何在有限算力的手机上跑通Gemma 4这类模型?端侧推理的量化、剪枝、KV Cache等关键技术等你解锁。