一句话速览:RAG解决“知”的问题——让模型拥有外部知识库;Agent解决“行”的问题——让模型拥有自主行动能力。两者构成AI助手的“记忆中枢”与“行动大脑”。
开篇引入

2026年4月8日,国产AI赛道迎来多个重磅消息:DeepSeek网页版正式上线“快速模式”与“专家模式”,这是其走红以来首次在产品端引入模式分层设计;智谱在同一天发布GLM-5.1,定价策略从“价格战”转向“性能溢价”;更值得期待的是,由梁文锋亲自带队的DeepSeek-V4已确定于本月发布,将在长期记忆、编程和多模态三大方向实现关键突破,有望重塑开源大模型的技术格局-1-7-5。
但在技术浪潮席卷而来的同时,许多开发者面临一个共同的困惑:RAG(检索增强生成)和Agent(智能体)到底是什么关系?什么时候该用哪个?面试时如何答出亮点?
本文将通过 “问题 → 概念 → 关系 → 示例 → 原理 → 考点” 的逻辑链条,帮你彻底理清这两个核心概念。
痛点切入:为什么需要RAG和Agent?
核心痛点:大模型“啥都会,但啥都不精”——知识过时、记忆有限、缺乏行动能力。
传统做法: 直接调用大模型API,让模型基于自身训练数据回答。
传统做法 response = llm.chat("我们公司的请假政策是什么?") 问题:模型训练数据截止于某个日期,无法知道最新政策
三大痛点:
知识时效性差:模型训练数据存在截止日期,无法获取实时/私有信息,容易出现“幻觉”(一本正经地胡说八道)
记忆能力有限:上下文窗口有限,长对话易遗忘,无法跨会话保留用户偏好
缺乏行动能力:只能“说”不能“做”,无法调用API、操作数据库、执行代码
解法逻辑:用RAG赋予模型“随时翻阅书籍”的能力 → 用Agent赋予模型“主动行动”的能力
H2 核心概念一:RAG(检索增强生成)
英文全称:Retrieval-Augmented Generation
一句话定义:在生成回答之前,先从外部知识库中检索相关信息,再将检索结果作为上下文输入模型进行回答。
生活化类比:RAG相当于给一个学富五车的学霸配上了一个“移动图书馆”。当被问到一个问题时,学霸先跑去图书馆查相关书籍(检索),然后翻看找到的资料(理解),最后结合自己的知识和查阅到的信息给出答案(生成)。
核心价值:
知识保鲜:企业文档更新后,只需重新索引即可让AI立即知晓,无需重新训练模型
遏制幻觉:让模型基于事实材料回答,显著降低“一本正经胡说八道”的概率
成本可控:相比微调(Fine-Tuning)动辄数万元的成本,RAG几乎是零成本的解决方案
工作原理(三步走):
索引阶段:将企业文档切片,通过Embedding模型转化为向量,存入向量数据库
检索阶段:用户提问时,将问题向量化,在向量数据库中做相似度检索,找出最相关的文档片段
生成阶段:将检索到的片段与问题拼接,输入大模型生成最终答案
H2 核心概念二:Agent(智能体)
英文全称:AI Agent(人工智能代理)
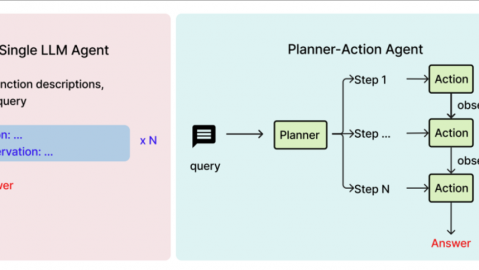
一句话定义:以大语言模型为“大脑”,能够自主感知环境、规划任务、调用工具、执行行动并持续学习优化的智能系统-32。
生活化类比:如果说大模型是一个只会“出点子”的超级顾问,那Agent就是这位顾问配上了“双手和双脚”。它不仅能告诉你“应该怎么做”,还能亲自动手去完成——查数据库、写代码、发邮件、调度API,全程不需要你一步步催促。
核心组件(LLM-Based Agent的五要素):
| 组件 | 功能 | 通俗解释 |
|---|---|---|
| 大脑(LLM) | 理解、推理、决策 | 总指挥 |
| 规划(Planning) | 将复杂目标拆解为子任务 | 排兵布阵 |
| 记忆(Memory) | 存储历史信息(短期+长期) | 记事本 |
| 工具使用(Tool Use) | 调用外部API/函数执行操作 | 工具箱 |
| 行动(Action) | 执行具体操作 | 动手干活 |
思维链(Chain of Thought, CoT) 是Agent进行规划的基础技术——引导模型一步步展示推理过程,将复杂问题分解为可解释的子任务链,从而提高处理复杂逻辑任务的准确性-32-。例如,不直接问“17×24等于多少”,而是引导模型先算20×17,再加4×17,让推理路径变得可见可调试。
ReAct(Reason + Act)框架 则是Agent在CoT基础上的进一步演进——要求模型在执行动作前先输出推理轨迹(Reason),再采取行动(Act),并在行动后观察结果(Observation),形成“思考-行动-观察”的闭环,有效解决了纯CoT模式下“想得对但做不对”的问题-31。
Function Calling(函数调用) 是实现Agent“工具使用”的核心运行机制——大模型输出结构化的JSON数据,触发预定义的代码函数或API,从而完成查询数据库、发送邮件等实际操作-32。
H2 概念关系与区别总结
一句话概括:RAG解决“知”的问题——让模型拥有知识库;Agent解决“行”的问题——让模型拥有行动力。
| 对比维度 | RAG | Agent |
|---|---|---|
| 核心定位 | 知识驱动的检索系统 | 目标驱动的决策执行系统 |
| 记忆性质 | 查询驱动,只读检索 | 任务驱动,可读可写 |
| 能力边界 | 检索+生成(知) | 规划+调用+执行+反思(行) |
| 典型场景 | 文档问答、知识库查询 | 自动数据分析、多步骤任务执行 |
| 实现难度 | 较低,适合快速落地 | 较高,需复杂编排与容错 |
RAG是Agent实现长期记忆的核心技术组件之一,而Agent是RAG能力边界之外的整体系统架构延伸-22-50。
H2 代码示例:从零实现一个简单RAG
pip install chromadb sentence-transformers import chromadb from sentence_transformers import SentenceTransformer 1. 准备知识库 documents = [ "DeepSeek-V4将于2026年4月发布,具备长期记忆和多模态能力。", "RAG(检索增强生成)通过外部知识检索提升答案准确性。", "AI Agent以大模型为大脑,能够自主调用工具执行任务。" ] 2. 初始化Embedding模型(将文本转为向量) model = SentenceTransformer('all-MiniLM-L6-v2') embeddings = model.encode(documents).tolist() 3. 创建向量数据库并插入数据 client = chromadb.Client() collection = client.create_collection("knowledge_base") collection.add( ids=[str(i) for i in range(len(documents))], embeddings=embeddings, documents=documents ) 4. 用户提问 + 检索相关文档 query = "DeepSeek V4什么时候发布?" query_embedding = model.encode([query]).tolist() results = collection.query(query_embeddings=query_embedding, n_results=1) 5. 将检索结果作为上下文生成答案 context = results['documents'][0][0] prompt = f"基于以下信息回答问题:\n{context}\n问题:{query}\n答案:" 调用大模型API... print(f"检索到的上下文:{context}") 输出:检索到的上下文:DeepSeek-V4将于2026年4月发布,具备长期记忆和多模态能力。
关键步骤标注:
SentenceTransformer:将文本转化为语义向量chromadb:向量数据库,存储和检索向量collection.query():语义相似度检索,找到最相关文档检索结果→大模型:实现了“先查后答”的RAG核心流程
H2 底层原理:RAG和Agent依赖哪些核心技术?
| 底层技术 | 支撑的功能 | 通俗解释 |
|---|---|---|
| Embedding(向量化) | RAG检索 | 将文本翻译成“语义坐标”,相似文本的坐标距离近 |
| 向量数据库 | RAG检索 | 专门存储“语义坐标”的数据库,支持毫秒级相似度检索 |
| 思维链(CoT) | Agent规划 | 引导模型一步步推理,将复杂问题拆解为子任务链 |
| Function Calling | Agent调用工具 | 模型输出结构化的JSON参数,触发预定义的代码函数 |
| 上下文窗口 | Agent记忆 | 限制模型一次能“看到”的信息量,当前主流模型支持128K~1M token |
💡 更深层原理(如Transformer自注意力机制、MoE混合专家架构等)涉及大量篇幅,本文不做展开,后续进阶文章会专题讲解。
H2 高频面试题与参考答案
Q1:RAG和Agent的核心区别是什么?(⭐⭐⭐⭐⭐)
踩分点:从“知 vs 行”角度切入,点明定位差异。
参考答案:RAG解决的是“知”的问题——让模型能够从外部知识库中检索信息,确保回答基于事实、减少幻觉,属于知识驱动系统。Agent解决的是“行”的问题——让模型能够自主规划任务、调用工具、执行行动,属于目标驱动系统。简单来说,RAG是Agent实现长期记忆的关键组件,而Agent是RAG能力边界的扩展。
Q2:如何通过Prompt解决大模型的“幻觉”问题?(⭐⭐⭐⭐)
踩分点:给出具体技术手段和工程化方案,而非泛泛而谈。
参考答案:核心在于“约束”和“接地”:
结构化约束:强制模型输出JSON格式,定义严格的Schema进行校验
思维链引导:要求模型先输出思考过程,再给出最终答案
拒答机制:在Prompt中明确“如果在参考资料中找不到答案,请直接回复‘不知道’”
少样本示例:提供3-5个标准的问答对作为示例,让模型模仿严谨风格-41
Q3:RAG的检索召回率如何提升?(⭐⭐⭐)
踩分点:展示对RAG工程细节的理解。
参考答案:主要手段包括:
混合检索:结合向量检索(语义匹配)和关键词检索(BM25,精确匹配)
重排序:检索后使用Cross-Encoder模型对候选结果重新排序,把最相关的排到前面
文档切片优化:控制切片大小和重叠程度,避免信息碎片化-
Q4:Agent最常见的失败场景有哪些?如何解决?(⭐⭐⭐⭐)
踩分点:列举真实生产中的坑,给出可落地的解决方案。
参考答案:三大失败场景:
工具调用失败:LLM生成的参数格式不对——解法:做参数校验层,格式不合法时让LLM重生成,加失败重试,关键调用做人工兜底
上下文溢出:对话轮数过多超出窗口——解法:做上下文压缩,提取关键信息,用滑动窗口控制长度
目标漂移:执行过程中偏离原始目标——解法:每一步都做目标对齐,定期反思总结,必要时重新规划-42
Q5:什么时候选择RAG,什么时候选择微调?(⭐⭐⭐)
参考答案:
RAG适用:知识频繁更新、需要引入私有数据、快速迭代、成本敏感——约80%的场景优先选RAG
微调适用:需要模型学习特定风格/语气/格式、RAG检索效果不理想、有充足的标注数据且预算充足——约20%的场景-23
H2 结尾总结
核心三句话:
RAG = 检索 + 生成,解决知识时效性和“幻觉”问题,是AI助手的“记忆中枢”
Agent = LLM + 规划 + 记忆 + 工具,解决自主行动问题,是AI助手的“行动大脑”
RAG与Agent的关系 = 记忆与行动相辅相成,RAG是Agent实现长期记忆的关键组件
学习建议:本文帮助建立基础认知框架,掌握RAG的检索-生成流程和Agent的五要素架构是下一步深入学习的必备基础。如有疑问或建议,欢迎留言交流!
📌 下一篇预告:深入剖析Agent的规划能力——从CoT到ReAct再到ToT的演进,以及多Agent协同架构的设计要点,敬请期待。